|
Aneesh Muppidi I am an incoming Stanford CS PhD student and currently a Rhodes Scholar at Oxford University, co-advised by Jakob Foerster and Joao Henriques. Email / Scholar / Follow on X / Github ▶︎ harvardPreviously, I completed my concurrent masters/undergrad (AB/SM) at Harvard in CS and Neuroscience. I was advised by Prof. Hank Yang at the Computational Robotics Lab, Prof. Samuel Gershman at Harvard's Kempner AI institute where I was a KURE fellow, and Ila Fiete at MIT. I was the President of the Harvard Computational Neuroscience Undergraduate Society and Harvard Dharma. I wrote for the Harvard Crimson. I also like film photography. |

|
▶︎ harvardPreviously, I completed my concurrent masters/undergrad (AB/SM) at Harvard in CS and Neuroscience. I was advised by Prof. Hank Yang at the Computational Robotics Lab, Prof. Samuel Gershman at Harvard's Kempner AI institute where I was a KURE fellow, and Ila Fiete at MIT. I was the President of the Harvard Computational Neuroscience Undergraduate Society and Harvard Dharma. I wrote for the Harvard Crimson. I also like film photography. |
|
Recent News
|
Open Source
|
Research |
|||||||||
|
/
|
|||||||||
|
|||||||||
|
|||||||||
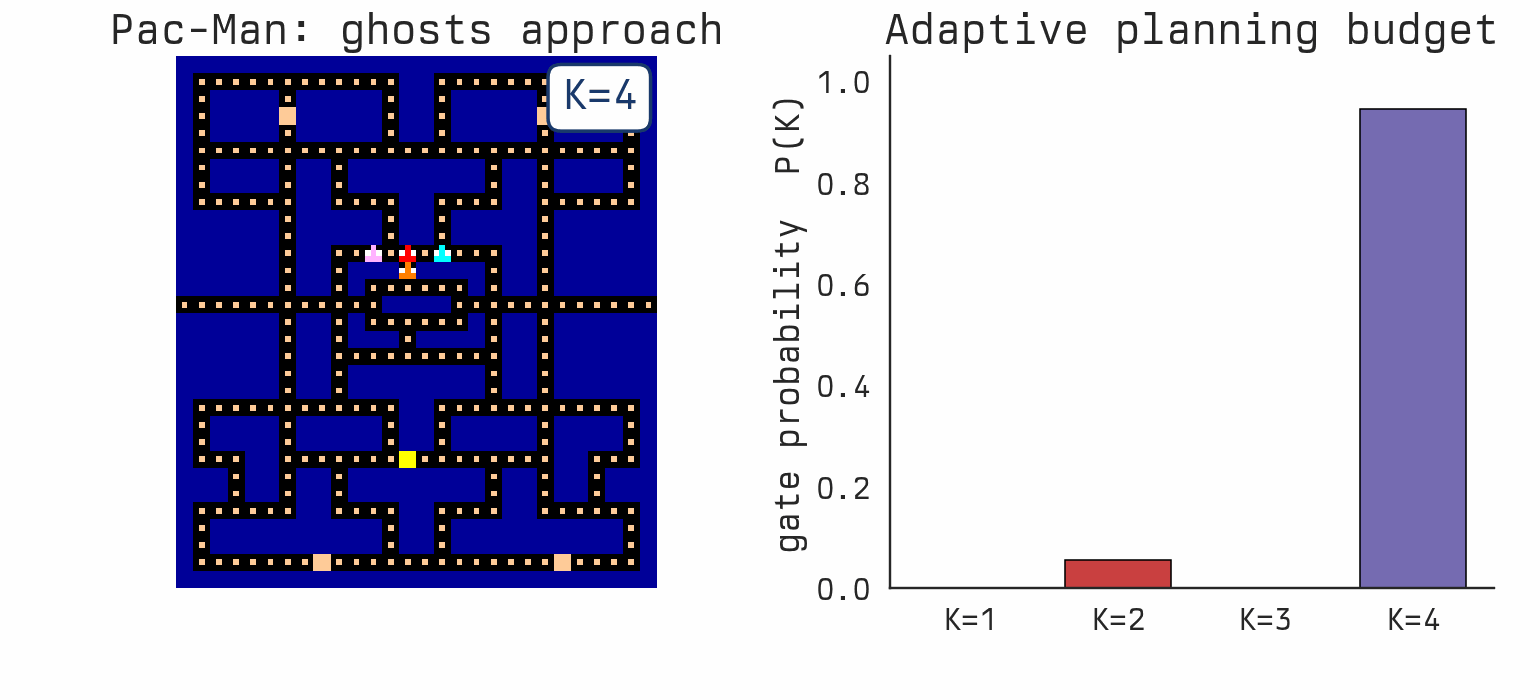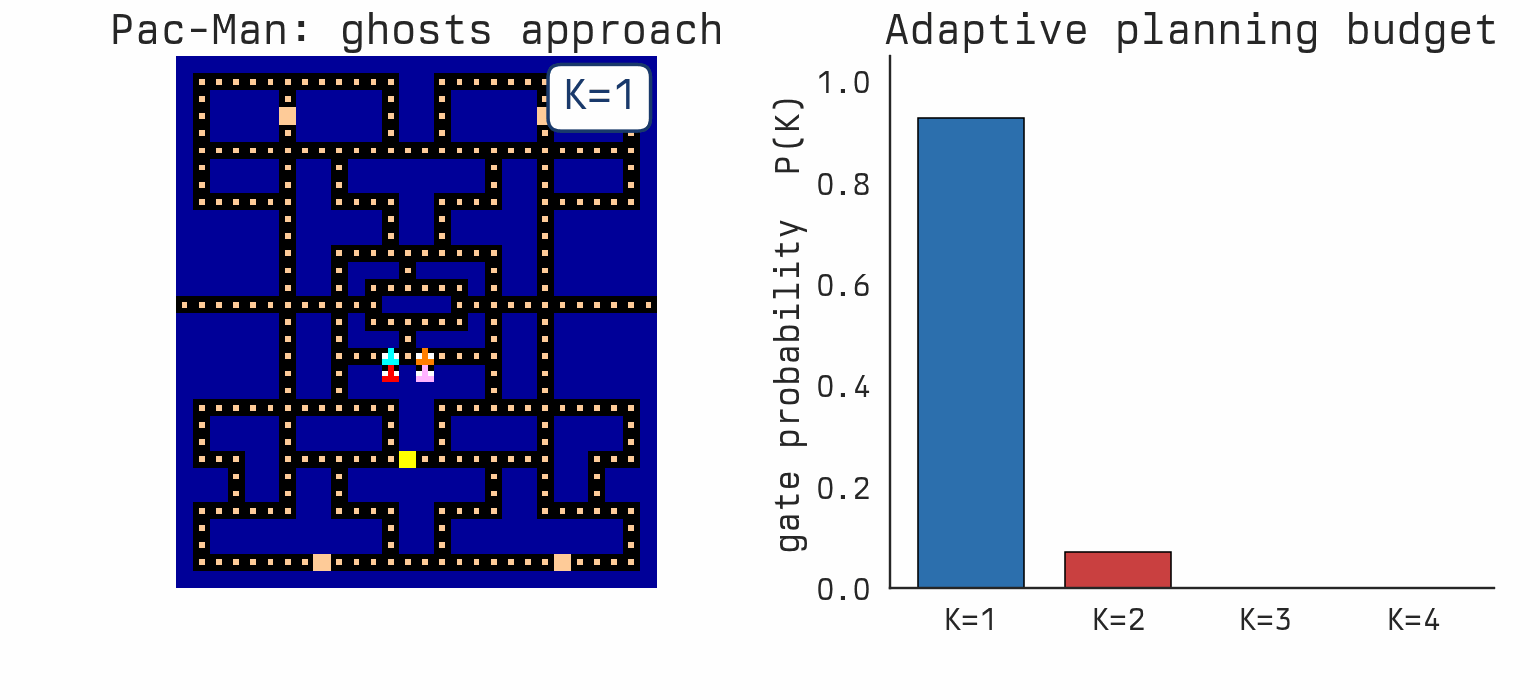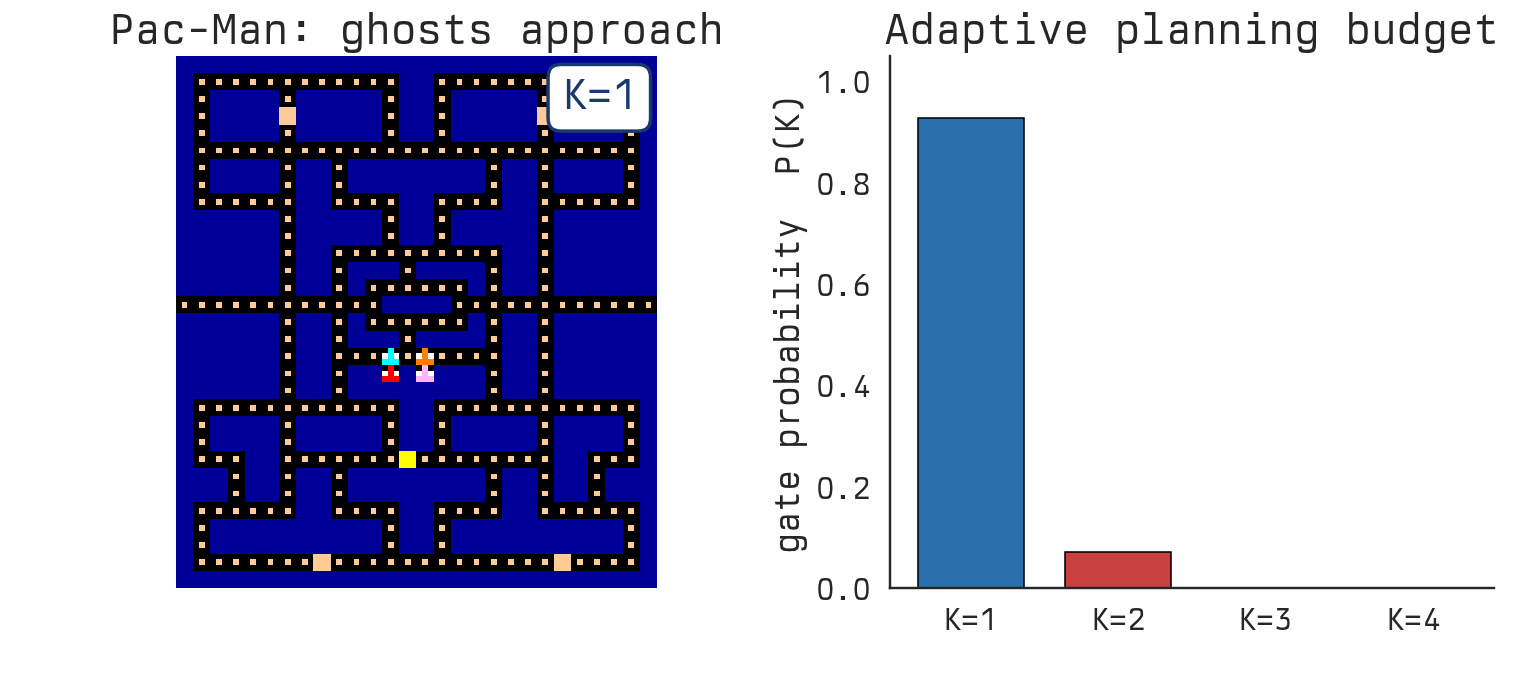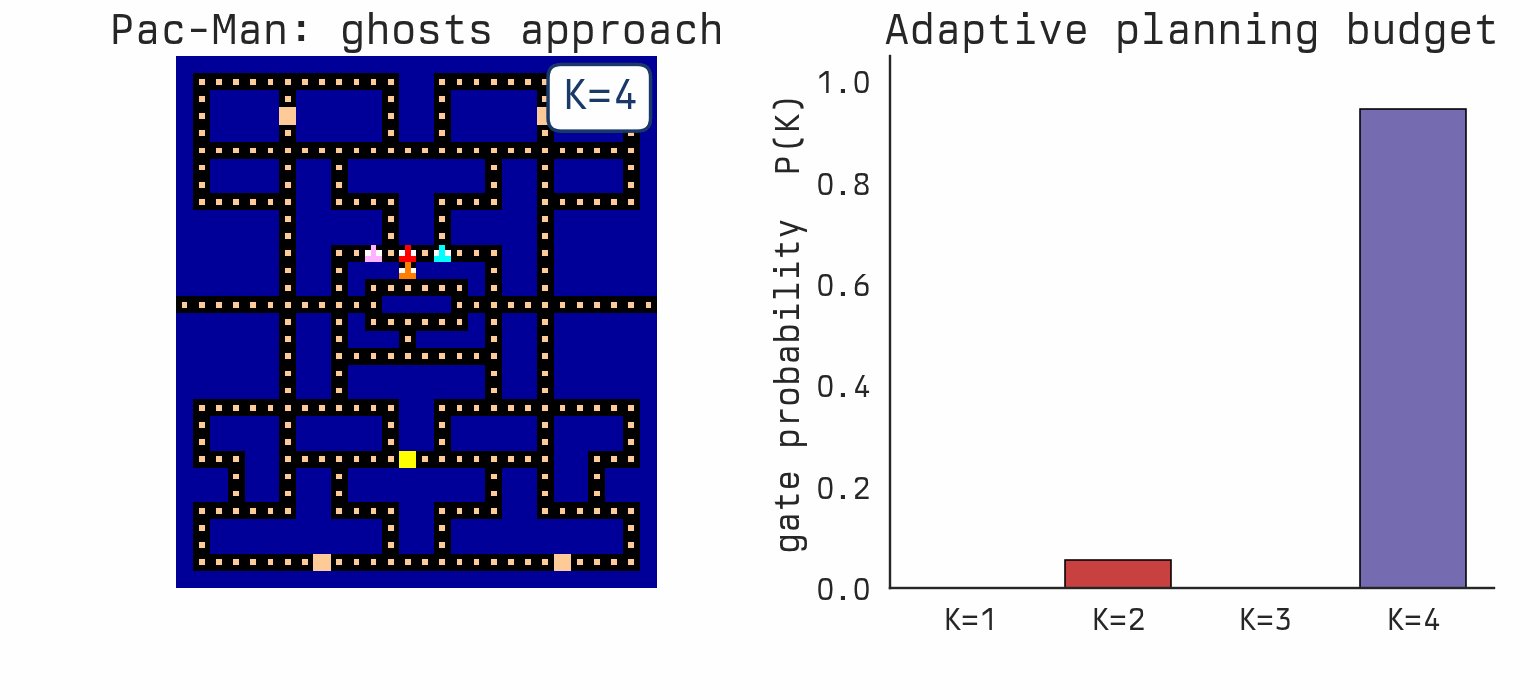
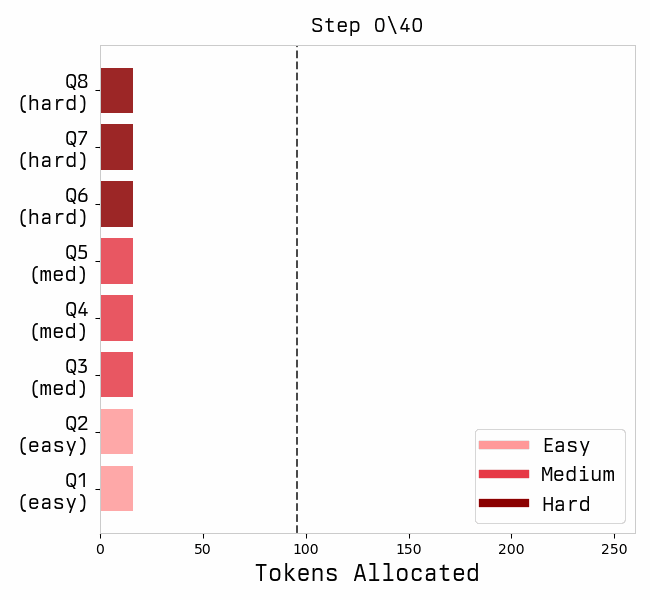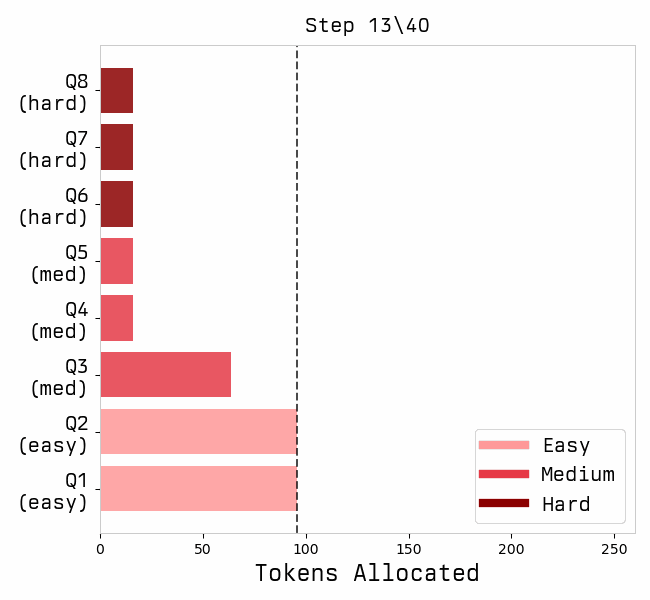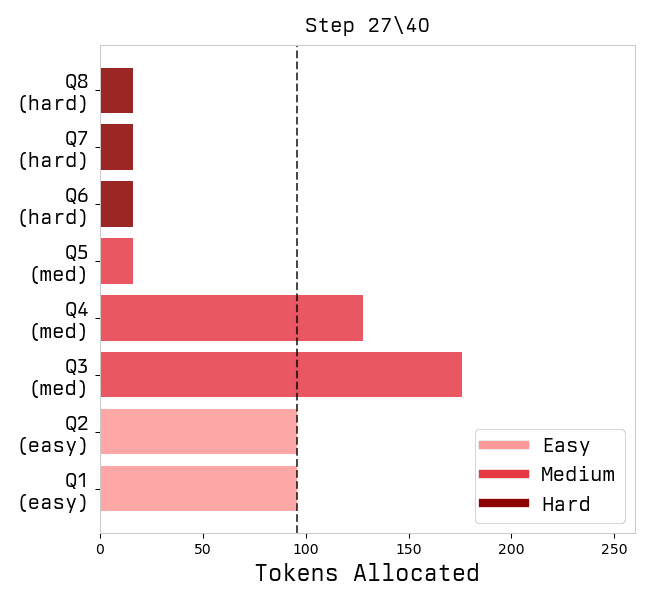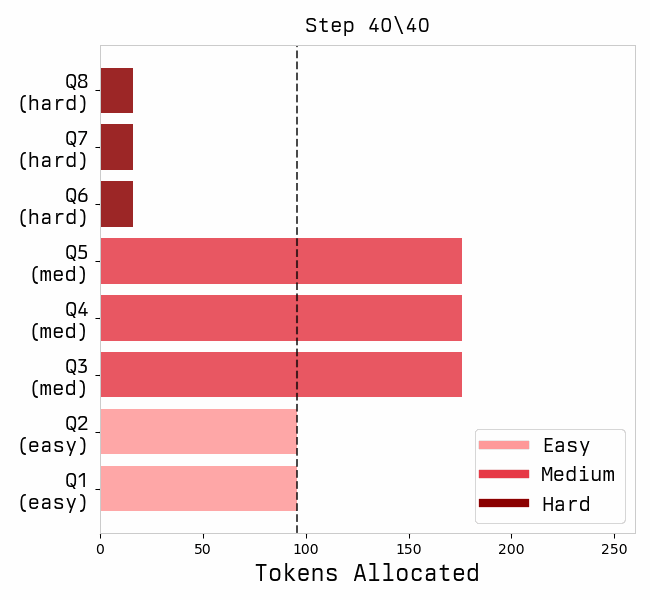



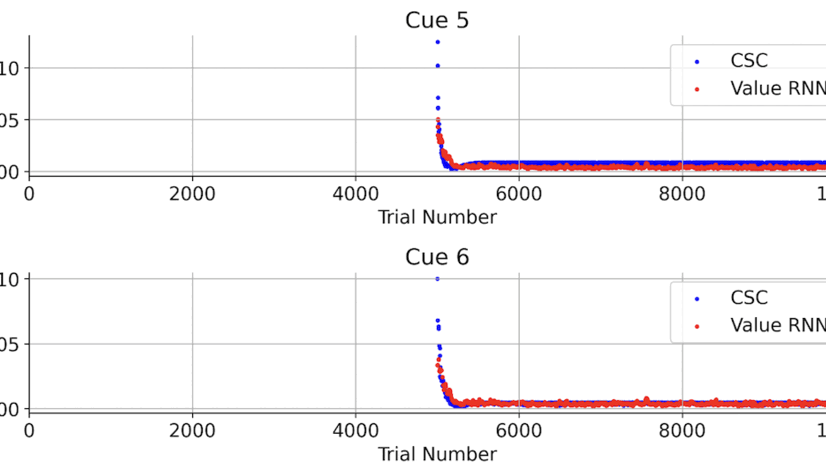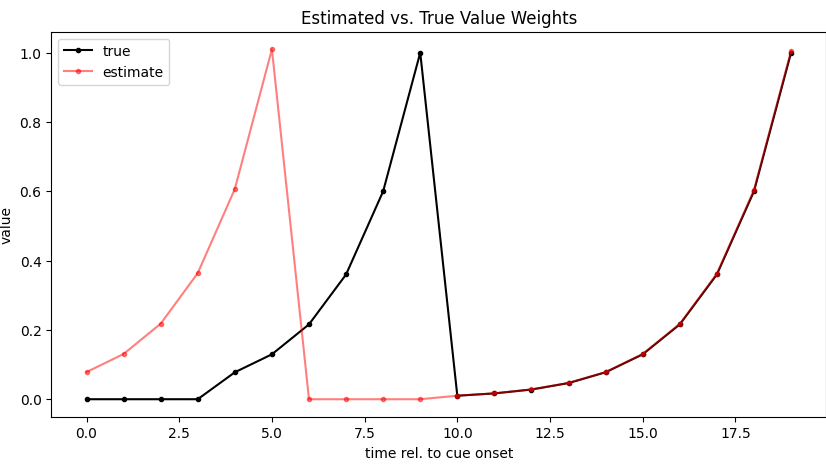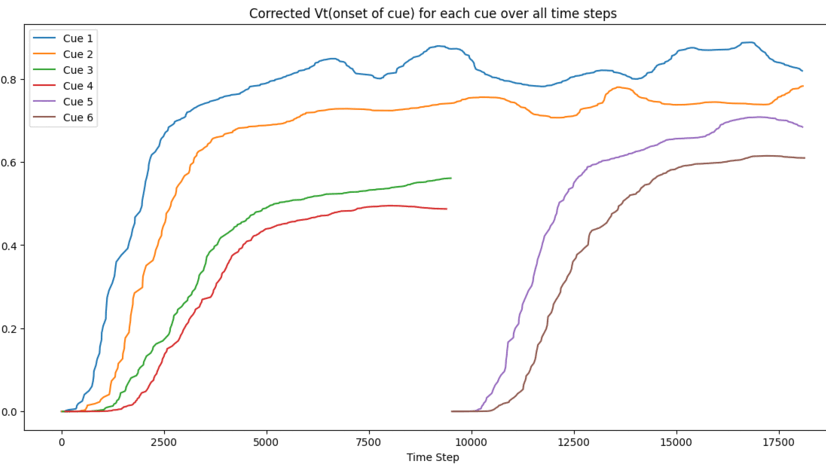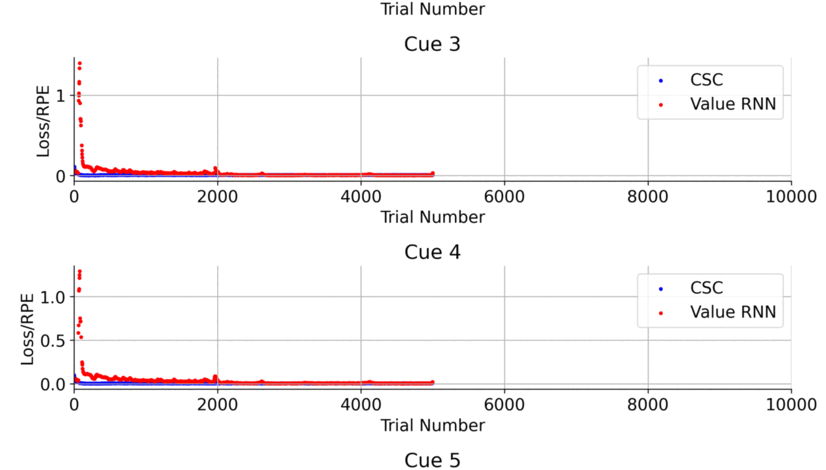

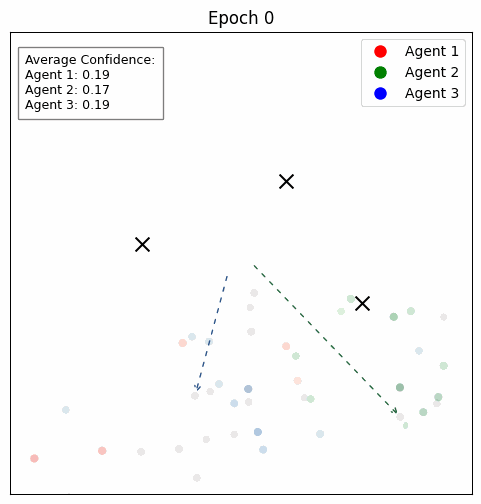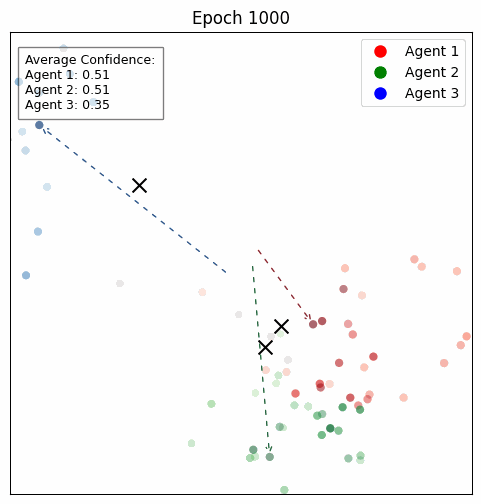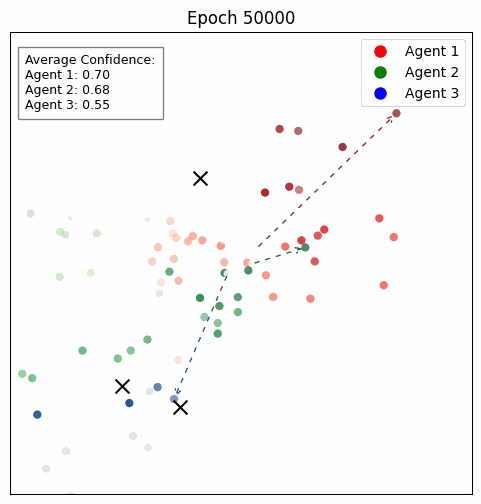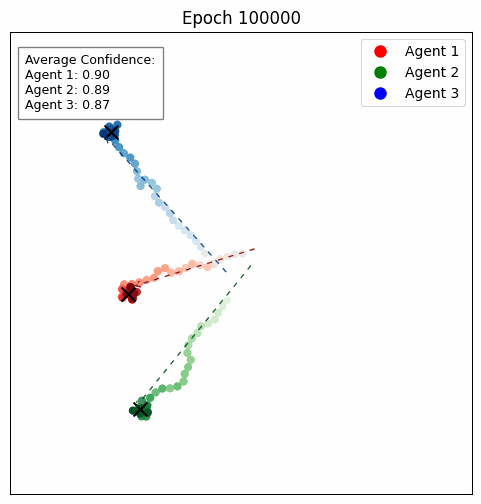
Favorites |
||

|

|

|

|

|

|
|
Modified from Jon Barron. |